# Install rTorrent to /usr/local/bin/rtorrent # rtorrent-linux-amd64 and rtorrent-linux-arm64 are available sudo wget https://github.com/jesec/rtorrent/releases/latest/download/rtorrent-linux-amd64 -O /usr/local/bin/rtorrent
# Make it executable sudo chmod +x /usr/local/bin/rtorrent
# Install as a systemd service (optional) # This example uses "download" user. Replace it with the an existing user that rTorrent should run with. sudo wget https://github.com/jesec/rtorrent/releases/latest/download/rtorrent@.service -O /etc/systemd/system/rtorrent@.service sudo systemctl daemon-reload sudo systemctl enable rtorrent@download sudo systemctl start rtorrent@download
# Maximum Socket Receive Buffer. 16MB per socket - which sounds like a lot, but will virtually never consume that much. Default: 212992 net.core.rmem_max = 16777216 # Maximum Socket Send Buffer. 16MB per socket - which sounds like a lot, but will virtually never consume that much. Default: 212992 net.core.wmem_max = 16777216 # Increase the write-buffer-space allocatable: min 4KB, def 12MB, max 16MB. Default: 4096 16384 4194304 net.ipv4.tcp_wmem = 4096 12582912 16777216 # Increase the read-buffer-space allocatable: min 4KB, def 12MB, max 16MB. Default: 4096 16384 4194304 net.ipv4.tcp_rmem = 4096 12582912 16777216
# Tells the system whether it should start at the default window size only for new TCP connections or also for existing TCP connections that have been idle for too long. Default: 1 net.ipv4.tcp_slow_start_after_idle = 0 # Allow reuse of sockets in TIME_WAIT state for new connections only when it is safe from the network stack’s perspective. Default: 0 net.ipv4.tcp_tw_reuse = 1 # Do not last the complete time_wait cycle. Default: 0 # only works from Linux 2.4 to 4.11 net.ipv4.tcp_tw_recycle = 1 # Minimum time a socket will stay in TIME_WAIT state (unusable after being used once). Default: 60 net.ipv4.tcp_fin_timeout = 30
############################################################################# # A minimal rTorrent configuration that provides the basic features #############################################################################
# Some default configs are commented out by #, you can override them to fit your needs # Lines commented out by ## are merely examples (NOT default)
# It is recommended to extend upon this default config file. For example: # override only some configs via command line: -o network.port_range.set=6881-6881 # or, on top of custom config: import = /etc/rtorrent/rtorrent.rc
# Some additional values and commands method.insert = system.startup_time, value|const, (system.time)
# Drop to "$(cfg.watch)/load" to add torrent schedule2 = watch_load, 11, 10, ((load.verbose, (cat, (cfg.watch), "load/*.torrent")))
# Drop to "$(cfg.watch)/start" to add torrent and start downloading schedule2 = watch_start, 10, 10, ((load.start_verbose, (cat, (cfg.watch), "start/*.torrent")))
# Listening port for incoming peer traffic network.port_range.set = 51418-51418 network.port_random.set = no
# Distributed Hash Table and Peer EXchange # Enable tracker-less torrents but vulnerable to passive sniffing # DHT and PEX are always disabled for private torrents #dht.mode.set = auto #dht.port.set = 51418 #protocol.pex.set = yes dht.mode.set = disable protocol.pex.set = no
# Limits for file handle resources, this is optimized for # an `ulimit` of 1024 (a common default). You MUST leave # a ceiling of handles reserved for rTorrent's internal needs! network.max_open_files.set = 10240 network.max_open_sockets.set = 500
# Send and receive buffer size for socket. Disabled by default (`0`), this means the default is used by OS # (you have to modify the system wide settings!) (`send_buffer_size`, `receive_buffer_size`) # Increasing buffer sizes may help reduce disk seeking, connection polling as more data is buffered each time # the socket is written to. It will result higher memory usage (not visible in rtorrent process!). network.receive_buffer.size.set = 4M network.send_buffer.size.set = 12M
# Memory resource usage (increase if you have a large number of items loaded, # and/or the available resources to spend) pieces.memory.max.set = 1800M #network.xmlrpc.size_limit.set = 16M
# Preallocate disk space for contents of a torrent # # Useful for reducing fragmentation, improving the performance # and I/O patterns of future read operations. However, with this # enabled, preallocated files will occupy the full size even if # they are not completed. # # If you choose to allocate space for the whole torrent at once, # rTorrent will create all files and allocate the space when the # torrent is started. rTorrent will NOT delete the file and free # the allocated space, if you later mark a file as DO NOT DOWNLOAD. # # 0 = disabled # 1 = enabled, allocate when a file is opened for write # 2 = enabled, allocate the space for the whole torrent at once system.file.allocate.set = 2
# HTTP and SSL network.http.max_open.set = 50 network.http.dns_cache_timeout.set = 25
# Path to the CA bundle. By default, rTorrent tries to detect from: # $RTORRENT_CA_BUNDLE (highest priority) # $CURL_CA_BUNDLE # $SSL_CERT_FILE # /etc/ssl/certs/ca-certificates.crt # /etc/pki/tls/certs/ca-bundle.crt # /usr/share/ssl/certs/ca-bundle.crt # /usr/local/share/certs/ca-root-nss.crt # /etc/ssl/cert.pem (lowest priority) ##network.http.cacert.set = /etc/ssl/certs/ca-certificates.crt
# Path to the certificate directory to verify the peer. The certificates # must be in PEM format, and the directory must have been processed using # the c_rehash utility supplied with openssl. # # For advanced users only, generally you should use network.http.cacert.set # to specify path to the bundle of certificates. ##network.http.capath.set = "/etc/ssl/certs"
# 安装Bencode_XS wget http://search.cpan.org/CPAN/authors/id/I/IW/IWADE/Convert-Bencode_XS-0.06.tar.gz wget https://rt.cpan.org/Ticket/Attachment/1433449/761974/patch-t_001_tests_t tar zxf Convert-Bencode_XS-0.06.tar.gz cd Convert-Bencode_XS-0.06 patch -uNp0 -i ../patch-t_001_tests_t perl Makefile.PL make make test sudo make install ## The patch-t_001_tests_t patch itself: --- t/001_tests.t.orig<>Sat Nov 15 14:41:13 2014 +++ t/001_tests.t<----->Sat Nov 15 14:41:27 2014 @@ -109,6 +109,7 @@ SKIP: { #we use Storable so we do not rely on bencode eval q{use Storable qw(freeze)};. skip "Storable not available", 12 if $@; + local $Storable::canonical = 1; local $Convert::Bencode_XS::COERCE = 0; is( freeze(bdecode('le')), freeze([]) ); is( freeze(bdecode('l0:0:0:e')), freeze(['', '', '']) ); # 安装rtorrent_fast_resume.pl脚本 sudo wget https://github.com/jesec/rtorrent/raw/master/doc/rtorrent_fast_resume.pl -O /usr/local/bin/rtorrent_fast_resume.pl
迁移脚本
move_torrent.sh
1 2 3 4 5 6
#!/bin/bash
for i in `cat $1`; do echo ${i} rtorrent_fast_resume.pl $3 "${2}/${i}.torrent" "${4}/${i}.torrent" done
$ sudo systemctl status rtorrent.service ● rtorrent.service - rTorrent service for Docker Loaded: loaded (/etc/systemd/system/rtorrent.service; disabled; vendor preset: enabled) Active: failed (Result: exit-code) since Wed 2022-05-18 06:17:52 CST; 10s ago Process: 140420 ExecStart=/usr/local/bin/rtorrent -o system.daemon.set=true (code=exited, status=255/EXCEPTION) Main PID: 140420 (code=exited, status=255/EXCEPTION) CPU: 912ms
May 18 06:17:51 nas systemd[1]: Started rTorrent service for Docker. May 18 06:17:51 nas rtorrent[140420]: rTorrent: loading 939 entries from session directory May 18 06:17:52 nas rtorrent[140420]: rTorrent: started, 939 torrents loaded May 18 06:17:52 nas rtorrent[140420]: rtorrent: random_device::random_device(const std::string&): device not available May 18 06:17:52 nas systemd[1]: rtorrent.service: Main process exited, code=exited, status=255/EXCEPTION May 18 06:17:52 nas systemd[1]: rtorrent.service: Failed with result 'exit-code'.
BitTorrent会将文件切分成称为pieces的块,每个块都有固定的大小(最后一个文件除外)。但是切分的块大小是不固定的,有时是256KB,有时是1MB。当每个对等点收到一个块时,它们就成为这个文件块的其他对等点的种子(become a seed of that piece for other peers)。
Once the BitTorrent client requests a sub-piece of a piece, any remaining sub-pieces of that piece are requested before any sub-pieces from other pieces.
在此图中,就是需要先下载该文件块的其他的所有子块,而不是开始下载另一个文件块。
② 稀有度优先(Rarest First)
BitTorrent下载的核心策略就是选择最稀有的文件块(pick the rarest first),所以我们要下载其他对等点拥有的最少的文件块。
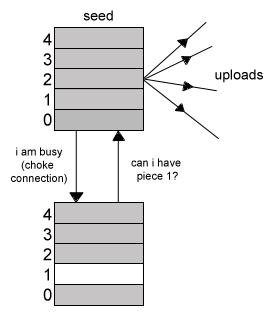
所以,根据这个原则:如果我们的上传速率很高,则会有更多的对等点允许我们从他们那里下载。即,**如果我们是优秀的上传者,我们可以获得更高的下载率(This means that we can get a higher download rate if we are a good uploader)**。这是BitTorrent协议的最重要功能。
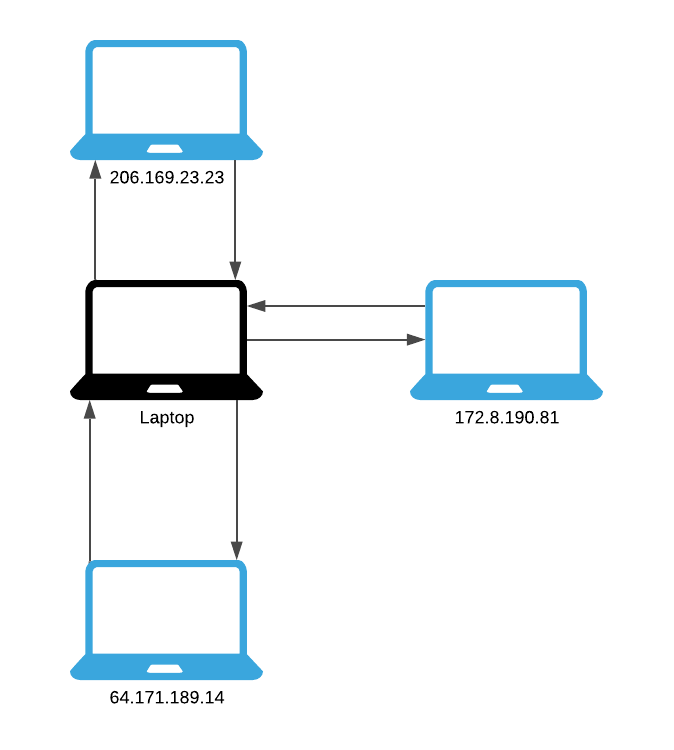
防御bt攻击最简单的方法是使用一个与你无关的IP地址,无论这是通过VPN还是其他服务(The simplest way to defend against a BitTorrent attack is to use an IP address not associated with you. Whether this is through a VPN or some other service)。
奇偶校验常见于数据传输中。比如 1 个字节(byte)由 8 个比特(bit)组成,但双方约定:只用 7 bit 来存储数据,剩下 1 bit 作为校验位(parity bit)。校验规则是:如果前面 7 bit 里 1 的数量为奇数(1, 3, 5, 7),则 parity bit 为 1;如果前面 7 bit 里 1 的数量为偶数(0, 2, 4, 6),则 parity bit 为 0。这样最终这个 byte 里 1 的数量一定是偶数,如果接收方发现 1 的数量不是偶数,那就说明出错了,一定是在传输过程中发生了比特翻转(bit flip),即本来是 0 的变成了 1,或本来是 1 的变成了 0。当然,如果这个 byte 在传输过程中发生了偶数个 bit flip,那校验倒也恰好能通过,但由于同一 byte 里有大于一个 bit flip 的概率非常低,所以奇偶校验在实际应用中还是非常简单有效的。
然而,上述奇偶校验只能知道「出错了」,但是无法知道「哪里出错了」,也无法修复出错的部分。但是在存储的时候,人们往往是知道哪里出错的。想像一下,如果上述 8 bit 不是存在同一 byte 里而是分散在 8 块磁盘上,这时候某一块磁盘突然挂了,你是明确地知道「哪里出错了」的(磁盘不转了),因此你根据其他 7 块磁盘里的 bit 值,来反推出坏掉的磁盘里存储的是 0 还是 1(把 1 的总数凑成偶数即可),也就是说,你可以利用 7 块健在的磁盘上的数据,修复坏掉的磁盘上的数据。
显然地,如果 8 块磁盘同时坏了 2 块或以上,那就有 00, 01, 10, 11 四种可能了,只有一个奇偶校验位的情况下是修复不了的。幸运的是,计算机科学家和数学家们早就研究出了其他更高级的冗余算法,可以使一组数据有两个或两个以上的校验位,用来在已知「哪里出错了」的情况下,修复出错的部分。SnapRAID 所用的冗余算法,用 N 个存储器用来存储数据,同时用 P 个存储器用来存放校验数据(P ≤ 6, P ≤ N),在总数 P + N 的存储器中,任意坏掉 X 个,只要 X ≤ P,就能用剩下存储器里的数据计算出坏掉的存储器里的数据。
Scanning disk d1... Scanning disk d2... Using 221 MiB of memory for the FileSystem. Initializing... Resizing... Saving state to /home/snapraid/snapraid.content... Saving state to /media/disk1/snapraid.content... Saving state to /media/disk2/snapraid.content... Saving state to /media/disk3/snapraid.content... Verifying /home/snapraid/snapraid.content... Verifying /media/disk1/snapraid.content... Verifying /media/disk2/snapraid.content... Verifying /media/disk3/snapraid.content... Syncing... Using 24 MiB of memory for 32 blocks of IO cache. 0%, 959 MB, 40 MB/s, CPU 1%, 24:08 ETA